
created at 2021.11.07
많은 서버에서 여러가지 이유로 중복해서 호출이 일어나는 api 가 있었다. 사실 그러라고 만들어 놓은 api 이기도 했지만, data center squeeze 테스트를 위해 트래픽을 한 쪽에 몰아 넣은 상황에서 uv 가 50k 정도 되었을 때 문제가 발생했다. 인스턴스를 너무 많이 띄우는 것 아니냐는 말과 함께 로직에 최적화가 되어있는게 맞는 것인지 하는 챌린지가 많이 들어왔었다. 그래서, 다방면으로 이유를 분석해서 수정을 진행했다. 훌륭한 분들이 많이 봐주시고 해결해 주신 것도 많고 배운 것도 많고 해서 효과가 좋았던 것들을 몇개 정리하기로 했다.
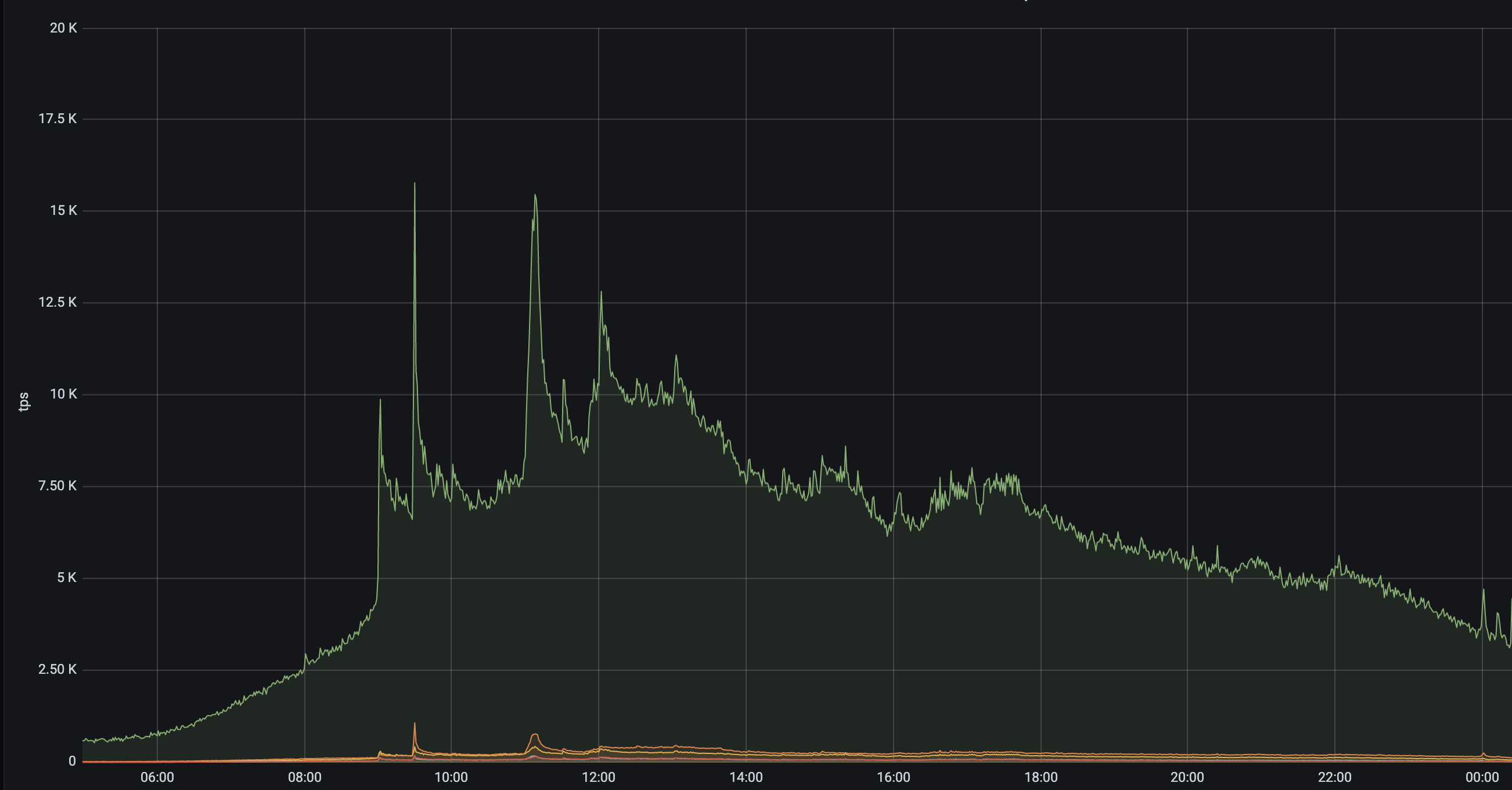
tps 15k
contents
redis cache 사이즈 줄이기
- why
- 콜 수도 많고 몽고 서치/cpu 작업도 커서 레디스 캐싱을 해두었는데, redis 쪽으로 네트워크 bandwidth가 너무 컸다. 네크워크 비용도 아깝고 언젠가는 문제가 됐을 수 있어서 수정했다.
- how
- 시리얼라이저를 바꿈
- 레디스 넣기 전에 snappy 를 사용했는데, gzip 으로 바꿨음 snappy vs gzip
- 캐싱 데이터를 바꿈
- 특정 작업의 결과물을 캐싱하던 것에서, 사용되는 파라미터 중 변동되는 것만 캐싱하고 서버가 작업을 매번 새로 하게 함
- 시리얼라이저를 바꿈
- result
- 두 작업 모두 cpu 를 손해보고 network 를 이득보는 작업이라, 효과는 확실했다. 레디스 인아웃은
500 MiB/s -> 95 MiB/s로 감소했지만, api 응답은 p507.5ms -> 12ms, p9528ms -> 32ms로 증가했다.
- 두 작업 모두 cpu 를 손해보고 network 를 이득보는 작업이라, 효과는 확실했다. 레디스 인아웃은
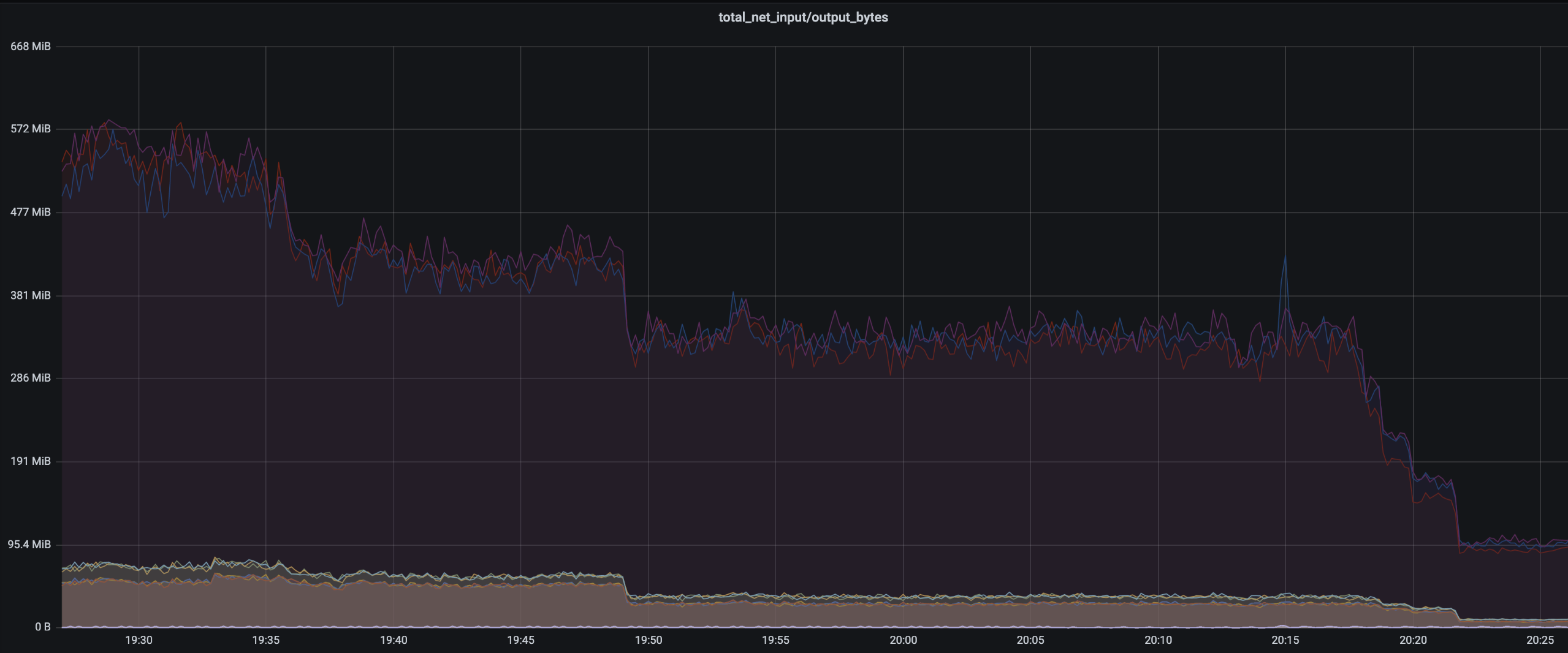
레디스 네트워크 in/out. 첫 드랍은 snappy -> gzip, 두번째 드랍은 캐싱데이터 수정
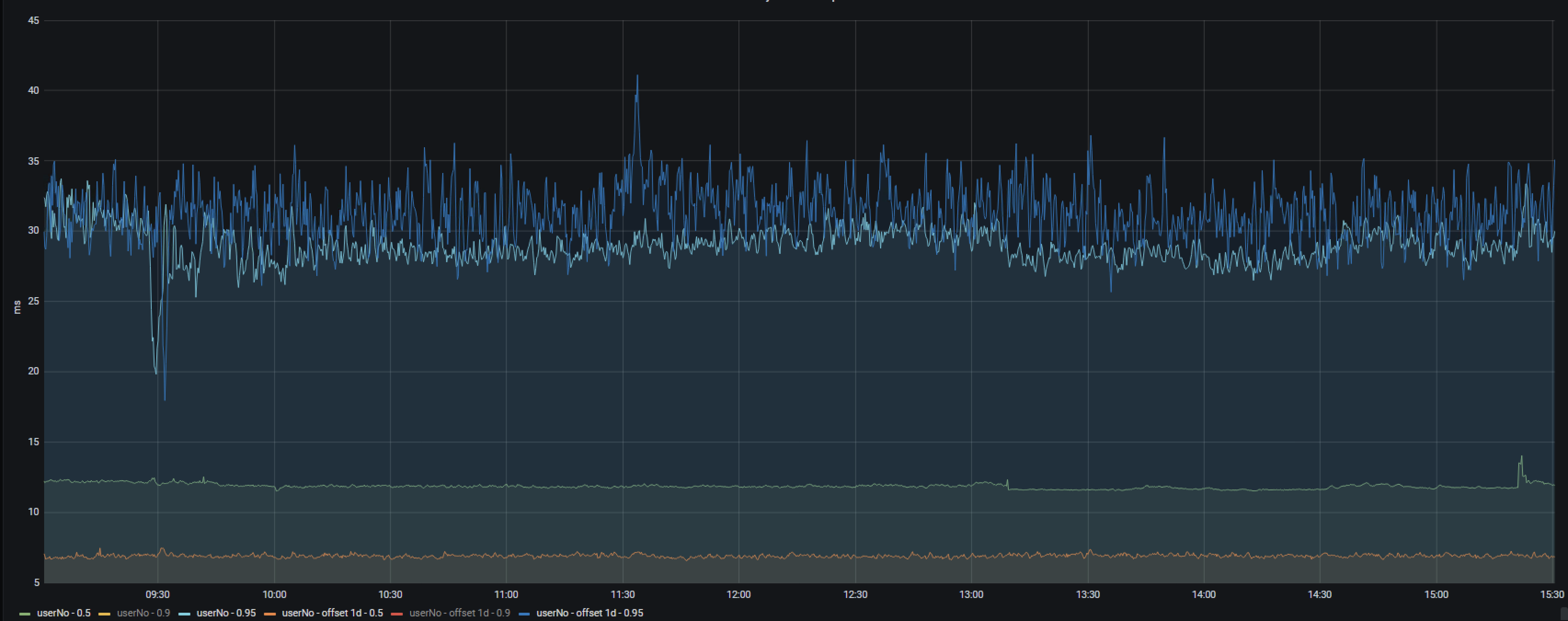
수정 후 전날과 응답속도 비교. 연산작업의 최적화가 필요해보인다.
mongos 이슈들
- mongos command max response 가 이상한 주기성을 가지고 늘어났음
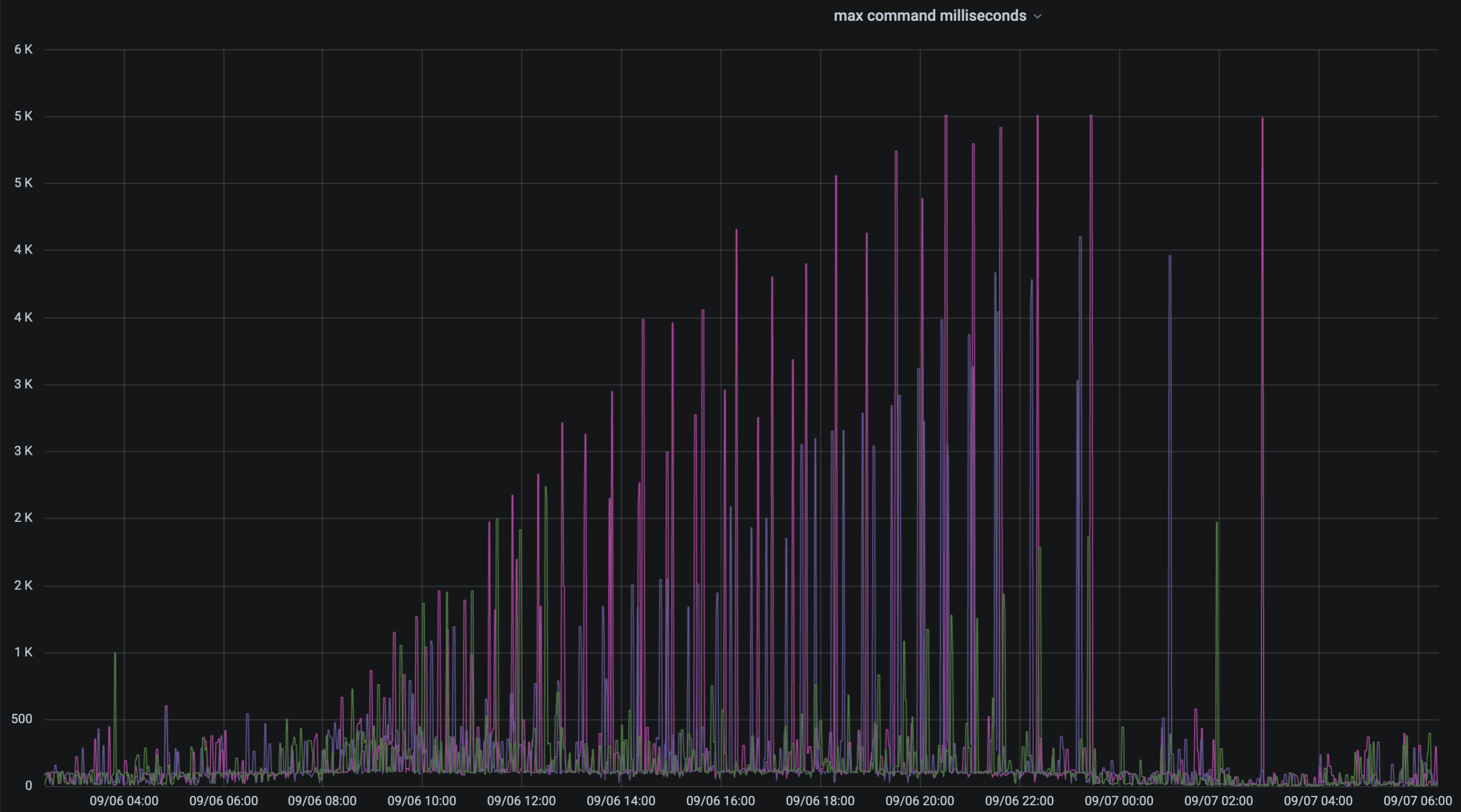
uv 가 높은 상황에서, mongos 별로 주기적으로 max response 가 증가하는 피크가 관측됨- why
- mongos 로그 중
LockBusy: could not acquire collection lock for ${dbName}.${collectionName} to split chunk를 발견 (관련 이슈) - 해당 command 가 날아가는 collection 은 5.7b 개의 다큐먼트를 들고 있고, 인서트도 활발히 일어나는 컬렉션이었다. insert 후에 chunk split 하던 와중 분산락을 획득하는 과정이 있는데, 이게 이슈가 있다고 리포트가 되었음
- mongos 로그 중
- how
- mongos 버전을 업데이트하는 것으로 해결.
- result
- 해결됨. 그러나…
- why
3개의 mongos 중 두개가 갑자기 죽었음
- why
- mongos 버전을 업데이트 하면서, 메모리 증설을 위해 dc 타겟을 바꾸고 호스트를 변경했었는데, 카나리 배포과정에서 몽고 커넥션 수가 호스트의 pid_max 값을 초과했음
- 두개의 mongos 의 pid_max 값이 리눅스 system default 값이었고(32768), 기존 mongos 는 4백만 정도로 세팅을 해서 사용중이었다.
root@32899a32399f:/# cat /proc/sys/kernel/pid_max 32768 - 참으로 운이 좋게 같은 세팅값의 세번째 mongos 는 살아있어서, mongos1,2 으로 타임아웃이 잠깐 난 후에 mongos3 으로 이용하였으나 아찔했던 상황
- how
- max_pid 값 늘림
cat /etc/sysctl.d/91-mongos.conf | grep kernel_pid_max kernel_pid_max=4194303
- max_pid 값 늘림
- result
- 해결됨
- 해결됨
- why
- 샤드 추가
- why
- batch insert 시에 큰 도움이 된다.
- 부하시간 대에 혹시나 swap 메모리로 가게 되면 리스폰스 타임에 문제가 갈 수 있고, 커넥션 타임아웃이 나고, 리스폰스 타임아웃이 나고, 이곳 저곳이 터지고…
- how
- mongo cluster 에 샤드 하나를 추가했다. 총 3개가 됐다. 내가 한 건 아니지만… 공식 가이드
- 유휴시간에만 rebalance 를 돌리도록 해두었는데, 10b 가 넘어가는 총 다큐먼트 때문에 리밸런스 완료는 요원한 상황이다.
- why
- 기타
- 다큐먼트 n 개 짜리 컬렉션 서치 시에 in 절에 m 개의 밸류를 넣으면
O(m*log(n))만큼 걸린다. 그러나, 인덱스 서치속도가 그렇다는 것이고 어쨌든 disk io 때문에 커맨드 리스폰스 자체는 m 에 리니어하게 증가하여 훨씬 더 길어질 수가 있다. 그런 경우에, 서치 시에 프로젝션을 줘서 인덱스에 포함된 필드만을 가져오게 한다면 추가적인 disk io 가 발생하지 않기 때문에 큰 이득을 볼 수 있다. 물론 다큐먼트 5.7b 짜리 컬렉션에 필드 3개짜리 컴파운드 인덱스를 추가한다? 허허..
- 다큐먼트 n 개 짜리 컬렉션 서치 시에 in 절에 m 개의 밸류를 넣으면
application 로직 최적화
- 사전작업
- API 를 목적에 맞게 전부 분리함
- 하나의 api 가 여러 목적에 대해 작업을 해주고 있었다. 처음에는 하나의 목적이었으나, uv 가 늘어나면서 점점 목적이 추가가 됐는데, 이로 인해 메트릭을 분석하기가 어려웠다.
- 별도의 처리 없이 계산만 하여 return 하는 api
- 모든것을 처리하고 계산하여 return 하는 api
- 급한것만 처리하고 계산하여 return 하는 api
- user 정보를 업데이트하고 계산하여 return 하는 api
를 분리하고 목적에 맞게 메트릭을 추가하여 분석하기 시작했다.
- 하나의 api 가 여러 목적에 대해 작업을 해주고 있었다. 처음에는 하나의 목적이었으나, uv 가 늘어나면서 점점 목적이 추가가 됐는데, 이로 인해 메트릭을 분석하기가 어려웠다.
- mongo 메트릭 추가
- 몽고를 쓰던 곳이 많지 않아 common prometheus 작업이 될 때 몽고쪽은 메트릭 추가가 되지 않았었다. 따로 커맨드리스너를 추가하여 메트릭을 수집하기 시작했고, promql 으로 메트릭을 그리기 시작했다.
- 몽고를 쓰던 곳이 많지 않아 common prometheus 작업이 될 때 몽고쪽은 메트릭 추가가 되지 않았었다. 따로 커맨드리스너를 추가하여 메트릭을 수집하기 시작했고, promql 으로 메트릭을 그리기 시작했다.
- API 를 목적에 맞게 전부 분리함
- mongo search 를 최대한으로 줄였음
- 딱히 이유가 없고 했었어야 하는 개선인데, 변명해보자면, 모듈화가 꽤 잘 되어있는 api 였기에 몽고 서치가 꽤 자주 일어났다. 말하자면.. msa 구조의 시스템에서 하나의 api 스트림에서 거쳐가는 서버 모두가 유저정보를 필요로 해서 각자가 했던 유저서버를 호출하고 또 호출하게 되는… 그런… 비슷한 문제라고 생각을 하는데, (netflix 에서는 passport를 이용해 문제를 해결했다. 유저 정보를 REST 헤더에 넣어서 계속 사용) 뭐 어쨌거나 이건 단일 서버 내에서 문제고 구조를 꽤 수정하여 최대한 한 번 했던 몽고서치는 다시 하지 않도록 수정했다.
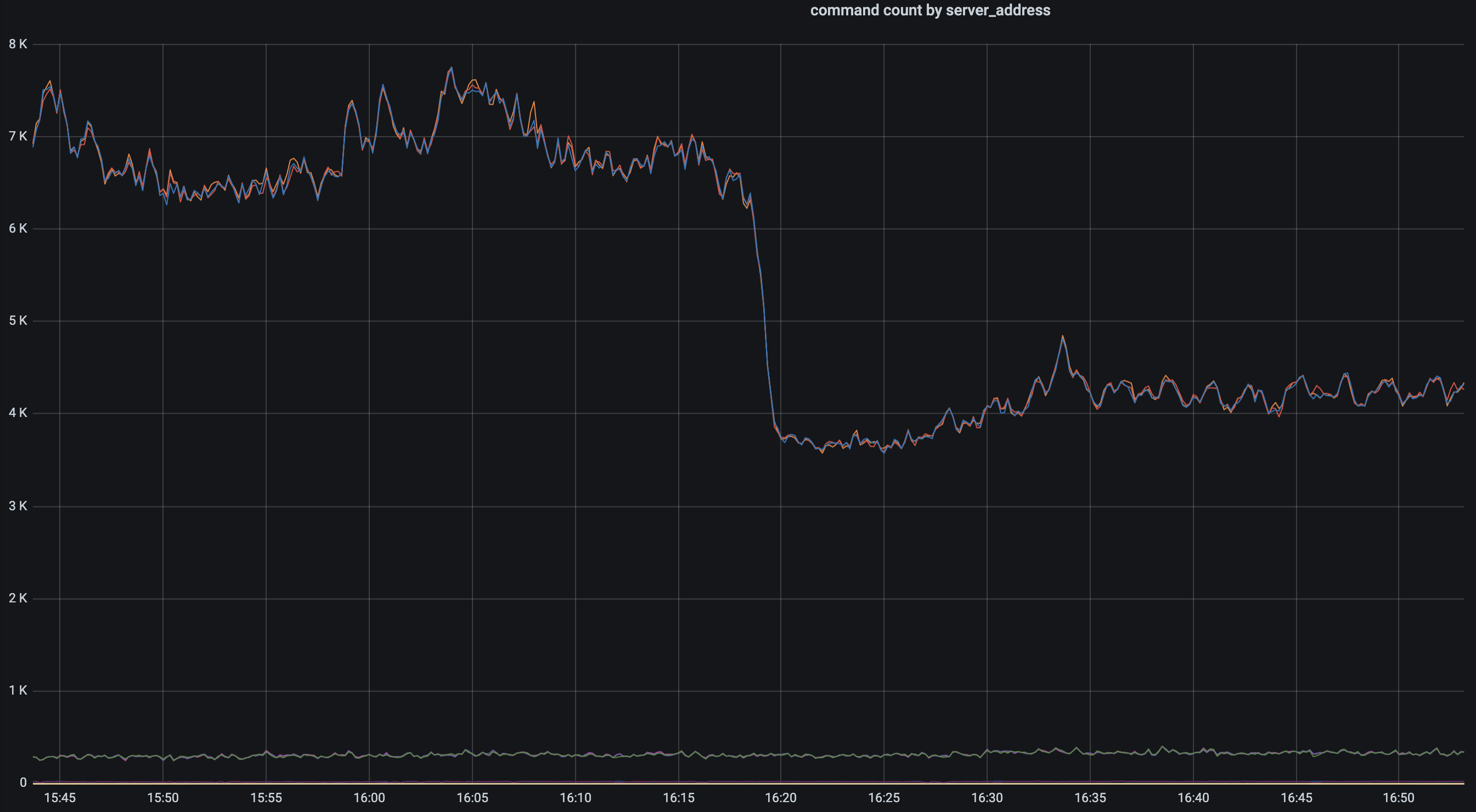
mongo call 개선 이후 call count
- mongo insert 작업을 병렬처리하였음
- 오랜만에 접속한 유저는 많은 수의 insert 가 일어나게 돼서, 이를 줄이기 위해 병렬처리를 진행함
- 코루틴을 쓰면 좋았겠지만… 쓰레드풀로 함ㅋ
- mongodb connection 수와 같은 pool size의
ThreadPoolTaskExecutor를 만들고 10k 정도의 큐를 둬서 만에하나 밀려도 oom 방지 (다음에 인서트하면 그만인 작업)
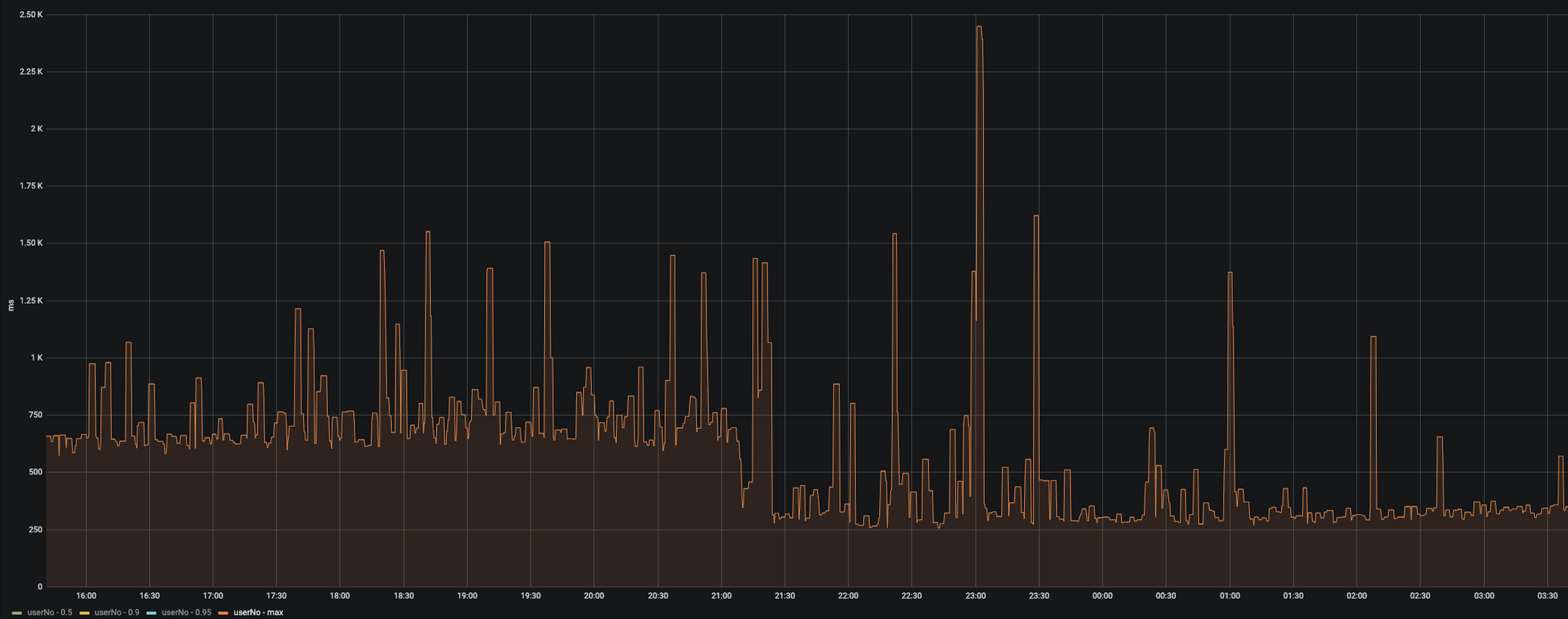
max response time 이 절반으로 줄었음. p50, p90 는 변화없고 p95 는 10퍼센트 정도 감소
- mongo search 를
readPreference=secondaryPreferred로 수정- 부하가 많이 가고 있는 다큐먼트 갯수 5b 짜리 컬렉션에 대해 disk io 도 분산하고 mongod 부하도 분산하고자 리드할 때 세컨더리를 보도록 수정했다. 서치량은 엄청나지만 살짝 밀려도 문제가 없는 컬렉션이기에 가능했고, cache hit rate 올라오기까지 리스폰스 타임이 조금 밀리긴 했지만 무리 없이 변경할 수 있었다. (가이드)
- 현재 구조상 샤드 별로 가용 secondary 가 2개인 상황인데,
secondaryPreferred를 하면 어째 한쪽 세컨더리 mongod 로만 리퀘스트가 간다.
- redis 캐싱 시간을 늘리기 위해 redis 에 저장되는 데이터를 최소화
- why
- redis 캐싱 시간을 유저별로 2min 으로 사용하고 있었는데, 2분 내에 변동이 적은 것이 확실하다면 캐싱시간을 늘려서 mongodb 부하 감소의 목적
- how
- as-is: 유저별로 A 오브젝트를 레디스 캐싱
- to-be: 유저별로 A 오브젝트의 id 를 레디스 캐싱 + 모든 A 오브젝트 리스트를 로컬캐싱하여 id 로 서치하여 A 오브젝트 획득
- result
- cons
- A 오브젝트의 변경이 있을 때 유저별 캐싱이 되어있어 invalidate 가 쉽지 않았기에 캐싱 시간을 늘리는데 한계가 있었으나, 캐싱시간을 늘릴수 있게됨
- pros
- 해시서치 과정과 로컬캐싱 메모리 추가사용 (별로 안아까움)
- 레디스 캐싱타임(2min)에 콜수가 엄청 많아서, 평균 앱 사용시간(~15min)까지 캐싱타임을 늘렸으나 사실상 거의 효과가 없었음.
- cons
- why
- cache stampede
- why
- 한 유저가 한 번 앱을 실행하면 서버의 여러 api 를 asynchronous 하게 호출하게 되는데, 각각의 api 들이 전부 이 api 를 호출해서 캐싱이 되어있지 않은 순간에 동시에 요청이 와서 cache stampede 가 종종 발생했다.
- how
- 정합성이 크게 문제되는 부분이 아니라 간단하게 단일 redis lock 을 잡고 ~10ms 쓰레드락 시킨 후에 다시 캐시히트를 받아내게 했다.
- result
- 응답시간에는 거의 변화가 없었다. 스퀴징중이 아니었기에 cpu 사용률이 줄거나 혹은 쓰레드 슬립때문에 톰캣 리퀘스트 쓰레드가 늘어나는 지도 확인하지 못했다.
- why
GZIP
사실 위의 어플리케이션 개선을 진행하면서, 많은 부분이 명백한 trade-off 를 가지고 있는데다가 크게 효과를 보이지 않는 개선도 많아서 불만이 많은 상태였다. 내가 만든 것은 아니지만 정말 사용성이 좋게 만들어져있는 api 였기에 호출량이 많았고, 그래서 tps 가 높아 컨테이너가 많다고 생각하고 있었기 때문이다. 어플리케이션 레벨에서는 니즈를 충족하면서 할 수 있는 모든 최적화를 해두었다고 생각했으나, 아는게 적어서 그렇게 생각했던 거였다.
요 api 는 서버 리스폰스가 100kB 정도 되는 비교적 큰 api 이다. 그래서 리턴할 때 Content-Encoding: gzip 으로 압축해서 보내고 있었고, 압축을 하고 나면 ~32kB 로 꽤 효율이 좋았다. 이거를 SRE 분께서 apm 을 분석하다가 발견해주셨는데, 요 과정이 시간이 오래 걸리더라. 사실 비정형 json 아웃풋이었기에 serialize 가 오래 걸리나? 비정형이라 kryo/proto 뭐 할 수 있는게 없겠다 생각을 하고 있었는데, gzip 압축이 문제가 될 수 있다는걸 찾아주시고 해결해주셨다. 아예 모르던 부분에서 개선이 가능하다는 걸 확인해서 또 한번 겸손이 필요한 시기임을 깨달았다.
gzip 에는 compression level이 있다. BEST_SPEED~BEST_COMPRESSION 으로 압축 레벨이 올라갈수록 압축률은 높아지고 압축 속도는 떨어진다. spring boot 의 엔진으로 쓰고 있는 톰캣은 java.util.zip.GZIPOutputStream의 디폴트인 레벨 6 을 사용하는데, 이 값을 변수 등으로 설정해 줄수가 없어 org.apache.coyote.http11.filters.GZIPOutputFilter 클래스를 그대로 오버라이드 한 후에 compression level 만 BEST_SPEED 로 변경하여 적용해 보았다.
@Override
public int doWrite(ByteBuffer chunk) throws IOException {
if (compressionStream == null) {
compressionStream = new GZIPOutputStream(fakeOutputStream, true) {{
def.setLevel(Deflater.BEST_SPEED);
}};
}
...
}
사실 gzip 압축 레벨을 낮추는게 무슨 큰 의미가 있겠냐 싶어서 의심이 들었는데, 결과는 아주 놀라웠다. compression 효율은 조금 떨어져서 38kB 로 약 15퍼센트 정도 손해를 봤지만, 응답속도는 p50 에서 12.5ms -> 7.8ms, p95에서 26.1ms -> 21.1ms 로 5 ms 정도나 떨어졌던 것이다. 아니 내가 이거 개선하려고 진짜 이것저것 다해봤는데.. 이게 gzip 압축레벨 바꿔서 해결된다고? 아..

gzip 압축레벨만 낮췄는데 극적인 효과가..
데이터 사이즈가 클수록 효과가 큰걸까? 후.. 정말 아는 게 없다고 느낀 하루였다.
실제로 93k 정도 되는 json object 를 만들어서 gzip 압축을 해보니, 압축하는 속도만 해도 차이가 컸다.
objectNode bytes size: 93154
compressed size: 25796 (DEFLATED(8))
compressed size: 93182 (NO_COMPRESSION(0))
compressed size: 29830 (BEST_SPEED(1))
compressed size: 25796 (BEST_COMPRESSION(9))
compressed size: 25849 (DEFAULT_COMPRESSION(-1))
2.701 milliseconds << DEFLATED(8)
0.101 milliseconds << NO_COMPRESSION(0)
0.829 milliseconds << BEST_SPEED(1)
2.665 milliseconds << BEST_COMPRESSION(9)
2.122 milliseconds << DEFAULT_COMPRESSION(-1)
어쨌거나 이런식으로 남의 클래스 자체를 오버라이드 하는 방식이 마음에 들지 않아서, 다른 방안을 봤는데 서버의 server.compression.enabled 옵션을 꺼서 Content-Encoding 하지 않고, 컨테이너에 사이드카로 붙어있는 envoy 에 envoy.compression.gzip.compressor 설정을 넣어 압축을 envoy 가 수행해서 헤더를 붙여 내보내는 방식이다. 이건 따로 서버가 해주지 않아도 돼서 괜찮지만, 현재 프로젝트가 여러 환경에서 동시에 서빙되고 있는 프로젝트라 환경 디펜던시가 걸리는게 영 께름칙했다. 뭐 이리저리 다 께름칙한 방법 뿐이라.. 우선 GZIPOutputFilter클래스를 오버라이딩 해서 쓰고는 있는데, 그래! 버전업을 하지 말자!
springboot의 다른 글 보기