
created at 2022.11.06
런타임 중의 자바 어플리케이션을 프로파일링해서 문제점을 찾아내고, 개선했다.
apt-get update &&\
apt-get install -y wget &&\
cd /tmp &&\
wget -q https://github.com/jvm-profiling-tools/async-profiler/releases/download/v2.7/async-profiler-2.7-linux-x64.tar.gz &&\
tar xzvf async-profiler-2.7-linux-x64.tar.gz &&\
cd async-profiler-2.7-linux-x64 &&\
./profiler.sh -d 60 -e cpu,alloc -f ./$(echo $APP_NAME)-$(echo $DEPLOY_VERSION).jfr 1
-e cpu,alloc 옵션은 프로파일링 대상에 cpu clock 이랑 mem alloc 을 포함시키도록 한다. 마지막 인자 1이 pid 이고, 여러 옵션은 여기 에서 확인 가능하다.
떨궈진 jfr 을 적절한 프로파일링 툴(여기선 intellij)으로 확인하면 된다.

cpu 샘플 전체 2252개 중 473개를 차지하는 것
아니 이런….!! 이런 게 나왔다. java.time.ZonedDateTime.parse 에서 발생하는 exception 생성 코드가 cpu 전체의 20퍼센트를 먹고있었다! 해당 코드는 다음과 같았다.
val formatters = listOf("yyyy", "yyyy-MM", "yyyy-MM-dd", ... ) // 22가지 포맷
.map { it.toDateTimeFormatter() }
fun parse(dateString: String): ZonedDateTime? {
formatters.forEach {
try {
return ZonedDateTime.parse(dateString, it)
} catch (e: Exception) {}
}
return null
}
다양한 포맷의 시간을 파싱하기 위한 코드였는데, exception 을 생성하는것 자체가 큰 부하였음을 간과하였다. 그리하여 다음과 같이 코드를 수정하고, 낭비되던 20퍼센트의 cpu 를 회수하였다.
fun parse(dateString: String): ZonedDateTime? {
formatters.forEach { dtf ->
val position = ParsePosition(0)
val temporalAccessor = dtf.parseUnresolved(dateString, position)
if (temporalAccessor != null && position.errorIndex < 0 && position.index == dateString.length) {
return ZonedDateTime.parse(dateString, dtf)
}
}
return null
}
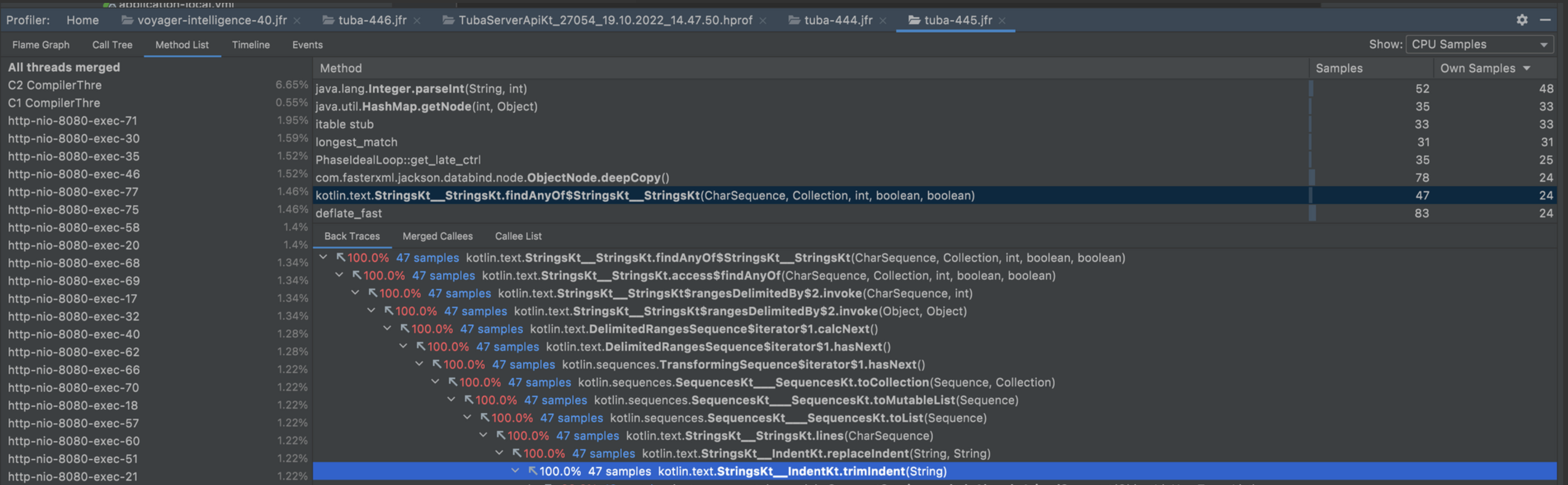
1494 샘플중 45샘플, 약 3퍼센트
이건 코틀린 코드 가독성을 높이기 위해 trimIndent를 사용했던건데, 잘 정리하여 없앴다. 가독성은 유지하되 불필요한 자원이 쓰이지 않게 조절했다.


mongodb 에서 쓰는 bson 의 ObjectId 만들 때 쓰이는 코드, 샘플링 된 메모리의 약 9퍼센트를 쓴다.
해당 코드는 다음과 같다.
private static byte[] parseHexString(final String s) {
byte[] b = new byte[OBJECT_ID_LENGTH];
for (int i = 0; i < b.length; i++) {
b[i] = (byte) Integer.parseInt(s.substring(i * 2, i * 2 + 2), 16);
}
return b;
}
문제가 되는 부분은 s.substring 이 b.length번 만큼, 즉 12번 반복되는 것이다. HexFormat 이 java 17 의 피쳐로 들어와서 자바 버전을 올리는게 가장 깔끔한 해결책이지만, 이런저런 이유로 그러지 못해 bson 라이브러리의 ObjectId 클래스를 새로 작성하여 사용했다. 수정한 코드는 다음과 같다.
fun parseHexString(string: String): ByteArray {
val bytes = ByteArray(string.length / 2)
for (i in bytes.indices) {
bytes[i] = fromHexDigits(string, i * 2).toByte()
}
return bytes
}
private fun fromHexDigits(string: CharSequence, index: Int): Int {
val high: Int = fromHexDigit(string[index].code)
val low: Int = fromHexDigit(string[index + 1].code)
return high shl 4 or low
}
private fun fromHexDigit(ch: Int): Int {
var value: Int = 0
if (ch ushr 8 == 0 && DIGITS[ch].also{value =it.toInt()}>= 0) {
return value
}
throw NumberFormatException("not a hexadecimal digit: \"" + ch.toChar() + "\" = " + ch)
}
리소스 개선 확인
그 외에 path matcher 를 ant path matcher 에서 path pattern parser 로 변경하였고, 기타 등등 수정해서
- cpu 사용률 30 퍼센트 절감
- api response time 20퍼센트 개선
- eden space alloc rate 25 퍼센트 절감
를 달성했다.
springboot의 다른 글 보기